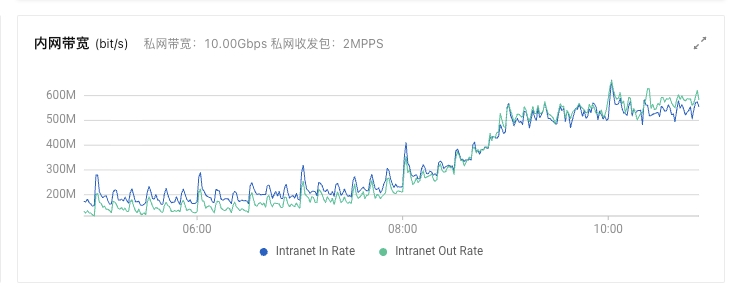
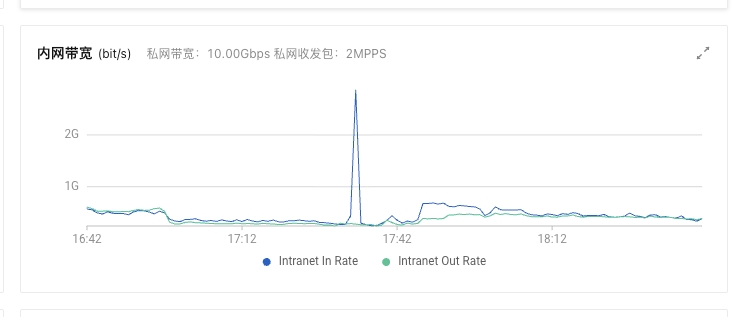
{"type": "server", "timestamp": "2023-10-25T01:35:18,510Z", "level": "WARN", "component": "o.e.t.OutboundHandler", "cluster.name": "business-log", "node.name": "es-b-194", "message": "sending transport message [MessageSerializer{Request{indices:data/write/bulk[s][r]}{70758574}{false}{false}{false}}] of size [21075] on [Netty4TcpChannel{localAddress=/127.0.204.194:57580, remoteAddress=127.0.204.193/127.0.204.193:9301, profile=default}] took [29403ms] which is above the warn threshold of [5000ms]", "cluster.uuid": "ArYy-qmCTbCQTDUI8ogsBg", "node.id": "PhjlCea6TNKh4rdZPyPDkA" } {"type": "server", "timestamp": "2023-10-25T01:35:18,510Z", "level": "WARN", "component": "o.e.t.OutboundHandler", "cluster.name": "business-log", "node.name": "es-b-194", "message": "sending transport message [MessageSerializer{Request{indices:data/write/bulk[s]}{70758608}{false}{false}{false}}] of size [1992] on [Netty4TcpChannel{localAddress=/127.0.204.194:57580, remoteAddress=127.0.204.193/127.0.204.193:9301, profile=default}] took [29403ms] which is above the warn threshold of [5000ms]", "cluster.uuid": "ArYy-qmCTbCQTDUI8ogsBg", "node.id": "PhjlCea6TNKh4rdZPyPDkA" } {"type": "server", "timestamp": "2023-10-25T01:35:18,510Z", "level": "WARN", "component": "o.e.t.OutboundHandler", "cluster.name": "business-log", "node.name": "es-b-194", "message": "sending transport message [MessageSerializer{Request{indices:data/write/bulk[s]}{70758614}{false}{false}{false}}] of size [5563] on [Netty4TcpChannel{localAddress=/127.0.204.194:57580, remoteAddress=127.0.204.193/127.0.204.193:9301, profile=default}] took [29403ms] which is above the warn threshold of [5000ms]", "cluster.uuid": "ArYy-qmCTbCQTDUI8ogsBg", "node.id": "PhjlCea6TNKh4rdZPyPDkA" } {"type": "server", "timestamp": "2023-10-25T01:35:18,510Z", "level": "WARN", "component": "o.e.t.OutboundHandler", "cluster.name": "business-log", "node.name": "es-b-194", "message": "sending transport message [MessageSerializer{Request{indices:data/write/bulk[s][r]}{70758686}{false}{false}{false}}] of size [9103] on [Netty4TcpChannel{localAddress=/127.0.204.194:57580, remoteAddress=127.0.204.193/127.0.204.193:9301, profile=default}] took [28603ms] which is above the warn threshold of [5000ms]", "cluster.uuid": "ArYy-qmCTbCQTDUI8ogsBg", "node.id": "PhjlCea6TNKh4rdZPyPDkA" } {"type": "server", "timestamp": "2023-10-25T01:35:18,510Z", "level": "WARN", "component": "o.e.t.OutboundHandler", "cluster.name": "business-log", "node.name": "es-b-194", "message": "sending transport message [MessageSerializer{Request{indices:data/write/bulk[s][r]}{70758737}{false}{false}{false}}] of size [12666] on [Netty4TcpChannel{localAddress=/127.0.204.194:57580, remoteAddress=127.0.204.193/127.0.204.193:9301, profile=default}] took [28603ms] which is above the warn threshold of [5000ms]", "cluster.uuid": "ArYy-qmCTbCQTDUI8ogsBg", "node.id": "PhjlCea6TNKh4rdZPyPDkA" }
普通节点(193)
1 2 3 4
{"type": "server", "timestamp": "2023-10-25T01:34:46,866Z", "level": "WARN", "component": "o.e.t.OutboundHandler", "cluster.name": "business-log", "node.name": "es-b-193", "message": "sending transport message [MessageSerializer{Request{indices:data/write/bulk[s]}{73855747}{false}{false}{false}}] of size [3828] on [Netty4TcpChannel{localAddress=/127.0..204.193:38616, remoteAddress=127.0.220.221/127.0.220.221:9301, profile=default}] took [35027ms] which is above the warn threshold of [5000ms]", "cluster.uuid": "ArYy-qmCTbCQTDUI8ogsBg", "node.id": "ZFQdNP4HSgCtPCnMfDdopw" } {"type": "server", "timestamp": "2023-10-25T01:34:46,866Z", "level": "WARN", "component": "o.e.t.OutboundHandler", "cluster.name": "business-log", "node.name": "es-b-193", "message": "sending transport message [MessageSerializer{Request{indices:data/write/bulk[s]}{73855763}{false}{false}{false}}] of size [14563] on [Netty4TcpChannel{localAddress=/127.0.204.193:38616, remoteAddress=127.0.220.221/127.0.220.221:9301, profile=default}] took [35027ms] which is above the warn threshold of [5000ms]", "cluster.uuid": "ArYy-qmCTbCQTDUI8ogsBg", "node.id": "ZFQdNP4HSgCtPCnMfDdopw" } {"type": "server", "timestamp": "2023-10-25T01:34:46,866Z", "level": "WARN", "component": "o.e.t.OutboundHandler", "cluster.name": "business-log", "node.name": "es-b-193", "message": "sending transport message [MessageSerializer{Request{indices:data/write/bulk[s]}{73855795}{false}{false}{false}}] of size [12940] on [Netty4TcpChannel{localAddress=/127.0.204.193:38616, remoteAddress=127.0.220.221/127.0.220.221:9301, profile=default}] took [35027ms] which is above the warn threshold of [5000ms]", "cluster.uuid": "ArYy-qmCTbCQTDUI8ogsBg", "node.id": "ZFQdNP4HSgCtPCnMfDdopw" } {"type": "server", "timestamp": "2023-10-25T01:34:46,866Z", "level": "WARN", "component": "o.e.t.OutboundHandler", "cluster.name": "business-log", "node.name": "es-b-193", "message": "sending transport message [MessageSerializer{Request{indices:data/write/bulk[s][r]}{73855813}{false}{false}{false}}] of size [10721] on [Netty4TcpChannel{localAddress=/127.0.204.193:38616, remoteAddress=127.0.220.221/127.0.220.221:9301, profile=default}] took [35027ms] which is above the warn threshold of [5000ms]", "cluster.uuid": "ArYy-qmCTbCQTDUI8ogsBg", "node.id": "ZFQdNP4HSgCtPCnMfDdopw" }
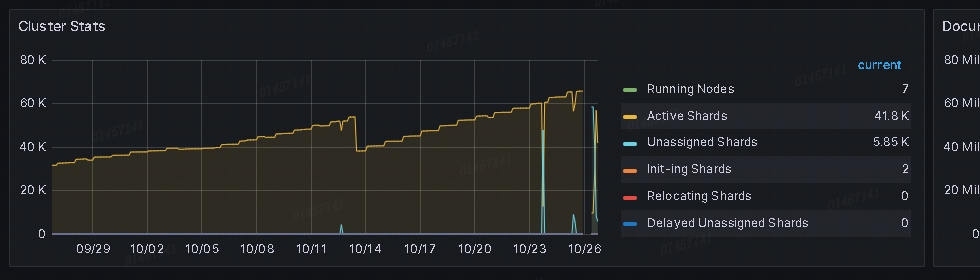
The number of shards a data node can hold is proportional to the node’s heap memory. For example, a node with 30GB of heap memory should have at most 600 shards. The further below this limit you can keep your nodes, the better. If you find your nodes exceeding more than 20 shards per GB, consider adding another node.